Probability and the Law
What does it mean to prove guilt beyond a reasonable doubt? Can we interpret legal standards of proof probabilistically? What is the role of probability and statistics in the courtroom? How are quantitative methods changing legal proceedings? Movie excerpts, courtroom cases, and academic scholarship will help us address these questions. No statistical or legal background is expected.
- Resources
- 1/10 - 1/24
- 1/31 - 2/21
- 2/28 - 3/14
Criminal Cases
JAN
The O.J. Simpson trial
- Dershowitz (1997), chap. 2
- Handout - Week 1
-
We began with the story of John, who was convicted for the possession of illegal pornographic material containing pictures of minors. Once his prison term ended, however, psychological tests showed that John posed a significant risk to society. According to the statistical tool STATIC-99, John was 25 percent likely to commit a sexual offense. Although there were doubts about the reliability of the risk assessment, John was consigned to a medical facility for an indefinite period of time. See the New Yorker article for more details.
We then looked at three examples of how statistics and probability can be used in criminal cases: the Shonubi case; a rape case involving DNA evidence; and a far-fetched hypothetical scenario. (These cases are described in the handout for week 1.) The three cases were meant to raise two closely related questions.
- Is a conviction legally justified if it is based on just statistical evidence?
- Is the high probability of a defendant's guilt (based on statistical evidence) enough to legally justify a conviction?
One idea is that statistical evidence (or at least, certain forms of it) lacks specificity: statistical evidence is not about the individual defendant, but about a group or category to which the defendant happens to belong. In contrast, DNA evidence seems to be more specific to the defendant.
After the break, we discussed some of the goals which trial proceedings should pursue: discovering the truth; deterrence; social reconciliation and the coming together of a community. The notion of truth is a multifaceted notion. For it can mean (a) an accurate reconstruction, picture, or narrative of what happened during the crime; (b) an accurate description of a set of facts about the crime (though such facts need not be organized to form a coherent reconstruction, picture, or narrative); (c) truth in the single case versus truth in the long run; (d) truth as finding an innocent defendant innocent versus truth as finding a guilty defendant guilty.
Finally we asked how statistical evidence fares in promoting any of the above goals.
We found that statistical evidence might fail to promote truth in the sense of (a) because numbers and statistics cannot contribute to reconstructing a coherent narrative of what happened during the crime. They are bare numbers, after all.
We also found that convictions based on statistical evidence might not promote the goal of deterrence. For statistics are not about an individual but groups or categories of people (see the specificity point above). So, if statistics alone could be the basis for a conviction, defendants would be convicted not because of what they did as individuals, but because of the behavioral tendencies of a group to which they belong. The goal of deterrence (understood as the goal of deterring individuals from committing wrongdoings) would thus be undermined.
Following Laurence Tribe's article, Trial by Mathematics (1971), we can also say that statistics and probability dehumanize the trial system, and thus they undermine the jury's function of mediating between the law in the abstract and the law as applied to human beings.There was no time to discuss the OJ Simpson case.
JAN
Probability
- Finkelstein and Levin (2001), sec. 3.1-3.2
- People v. Collins (1968)
- Reading Guide - Week 2
- Handout - Week 2
-
We began with the Massachusetts jury instructions about the meaning of the criminal standard of proof 'beyond a reasonable doubt.' Expressions that were used to clarify the standard included 'abiding conviction,' 'moral certainty,' 'reasonable certainty.' The instructions explicitly said that a probability was not enough to meet the standard. But if a probability is not enough, what could be enough? The issue here is that we cannot demand that guilt be proven with absolute certainty, so a probability short of certainty seems to be all we can require (unless we want to make convicting impossible).
Despite this resistance in understanding the criminal standard of proof probabilistically, we saw that the connection between probability and legal proceedings is a close one, also historically. I shared a couple of quotations with you. One was from Jacob Bernoulli who suggested that the moral certainty needed to convict should be equated to a probability threshold (e.g. 99/100 or 999/1000). The other quotation was from Cesare Beccaria who evocatively said that moral certainty is a probability, but a probability of a such a sort to be called certainty. The criminal standard of proof, then, would be a demand for an approximation of absolute certainty. But what are we to make of this? (For quotations from Bernoulli and Beccaria, see here.)
Setting aside this difficult question, we turned to the notion of probability, both its philosophy and the mathematics. The mathematics of probability is (almost) uncontroversial. Axioms and corollaries are stated in the handout. Regarding the philosophy of probability, we discussed different interpretations.
The frequency interpretation says that 'there is x chance that A' means that if a certain experiment or scenario is repeated a sufficiently large (possibly infinite) number of times, the probability of A is the relative frequency between the number of success cases (i.e. the number of cases in which A does occur) and the total number of repetitions of the experiment or scenario. (Example: I toss a coin a large number of times, and the relative frequency of heads is the probability of heads.) Note that this interpretation requires the repeatability (even hypothetical repeatability) of an experiment or a scenario. On this score, we wondered whether the frequency interpretation can be used in the legal case. In legal proceedings, after all, we are interested in the probability of a unique, and in principle, unrepeatable occurrence.
The second interpretation we considered was the classical interpretation. This is based on the idea of dividing the space of possibilities into a number of equally possible (or equally probable) cases and counting in how many of those cases the event A of interest is realized. One takes the ratio between the A-cases and all possible cases, and this gives the probability of A. The problematic issue here is not the repeatability, but how these equiprobable cases are identified. If a teacher is killed in a classroom, and there are 11 students present, it might seem that there are 11 equally possible cases or 11 possible ways the killing could have happened (each way having a different student as the killer). Although this is intuitive, there is a problem with this approach. How do we know that each student is equally likely to be the killer? Maybe some students are more prone to violence than others; maybe some students had a motive to kill the teacher and others did not. So, the space of equally possible/probable cases might not be made up of 11 cases. But how many? How should we describe those cases? And how can we identify them? This is difficult, and it is a problem for the classical interpretation.
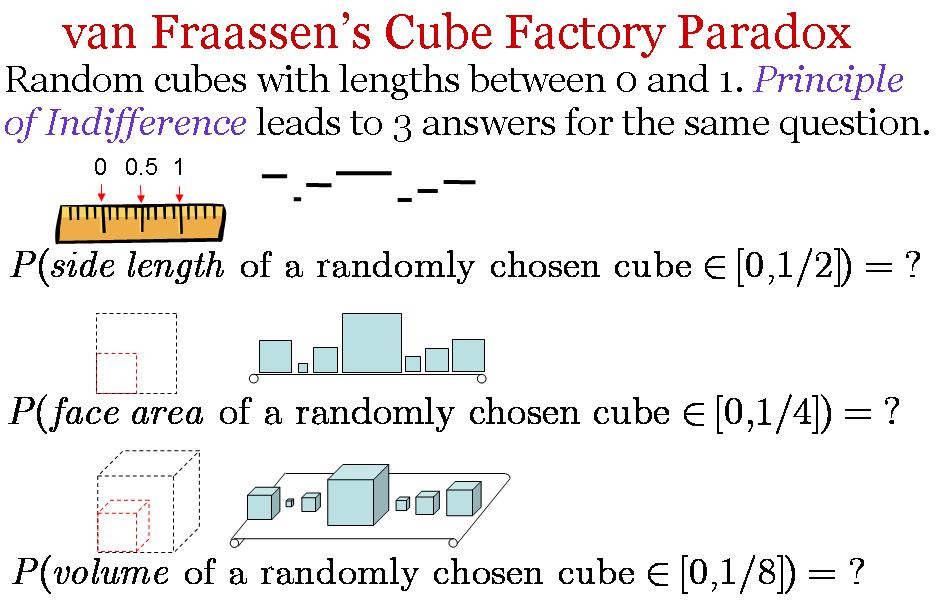
To make things even more difficult for the classical interpretation of probability, I gave you the random cube factory example. Suppose a factory produces cubes at random having side length between 0 and 1 cm. This means that any cube being made could have any side length between 0 and 1 cm. The probability that a cube has a side between 0 and 1/2 cm in length seems to be 1/2, right? And yet, the probability that a cube has a face area between 0 and 1/4 cm2 seems 1/4, right? But note that having a side between 0 and 1/2 and having a face area between 0 and 1/4 cm2 are the same event, just described differently. So, how come the probability of the same event is 1/2 and 1/4? This shows that how we divide the space of equally possible/probable cases is not obvious, and we can get counterintuitive results. For a visual statement of the problem, see here.
We also looked at two other interpretations of probability. One is sometimes called the epistemic or subjective interpretation. The basic idea is that one's estimate of the probability of an event A has to do with the strength of one's evidence for or against A. It is important to note that your evidence can include frequencies, though the probability would not itself be a frequency. This is probably (ah!) the most adequate interpretation in the legal case. In trial proceedings, we deal not with frequencies nor equiprobable cases, but with evidence for and against certain propositions.
Another interpretation (which is not really another interpretation) is what I called the model-based interpretation. According to it, the meaning of a probability statement has to do with the (probability) model on the basis of which the probability estimate is calculated. I suggested that the probability of an earthquake, or the probability of a natural phenomenon such as snow or rain, can be best understood within the model-based interpretation of probability. The idea here is that we need a model of the earth and of how earthquakes come about to estimate the probability of an earthquake.
A simple summary of the different interpretations of probability can be found here (along with some remarks about the probability of an earthquake). A more involved discussion can be found here.
After the break we discussed the Collins case. The Supreme Court of California in reviewing the case raised a number of objections, which are listed in the handout for this week. I emphasized that there are different questions we can ask about the case. Among these questions, there are:
- Was the description D (i.e. interracial couple, blond ponytail, mustache, etc.) actually a true description of the guilty couple?
- Was the estimate that D has a frequency of 1 in 12,000,000 a correct statistical estimate?
- Can we draw the conclusion that it is very unlikely that another couple besides the Collins is guilty?
- Can the Collins be convicted beyond a reasonable doubt?
The answer to the third question is also negative. To see why, we discussed the prosecutor fallacy, also called inversion fallacy, because it is the result of confusing P(A|B) and P(B|A). Now, let's assume (for the sake of argument) that the frequency 1 in 12,000,000 is a correct statistical estimate, and let's also assume that the guilty couple matches the description D. So, let's stipulate that the answer to the first two questions is positive. If so, is the answer to the third question positive? No. The frequency expresses the probability that a random couple (say, in California) would match the description D. So, P(match | random couple)=1 in 12,000,000. But 1 in 12,000,000 is NOT the probability that a couple matching the description D would be a random couple (or if you wish, it is not the probability that a couple matching the description would be an innocent couple, a couple unrelated to the crime). To say that P(random couple | match)=1 in 12,000,000 would be to commit the inversion or prosecutor fallacy.
One might reason as follows: the Collins match D, but D has a very low frequency/probability, so it is very unlikely that a random couple would match the description---all good up to here. Next step: so, it is very unlikely that the Collins are a random couple (i.e. it is very unlikely that the Collins are an innocent couple). The last step contains the inversion fallacy.
And what about the fourth question? Let's assume that the Collins are, in fact, very unlikely to be innocent, so very likely to be guilty. Is that enough to establish guilt beyond a reasonable doubt? This is the question we raised in our first class and again at the beginning of this class. A clear answer to this question is still missing, although many of us share the intuition that the answer here should be negative.
There was no time to discuss the Court's mathematical appendix. The appendix deals with the question, is there only one couple matching the description D or are there more than one such couples? Of course, if we could establish that there is only one D-couple (say, in California) and if we could be sure that the guilty couple was a D-couple, it would be certain that the Collins are the guilty couple. But is there only one D-couple? The Court calculations suggest that there is a non-negligible probability that more than one couple matches description D. This is the question of uniqueness. It will come up again when we discuss DNA evidence next week.
{kind=link}
JAN
DNA Evidence
- Wasserman (2008)
- Devlin (2007)
- Reading Guide - Week 3
- Handout - Week 3
-
We began with the Veysey case, which involved Veysay's house being on fire multiple times. What's interesting is that each time Veysey managed to get the insurance company to pay for the damages. Intuitively, it seems that this could not be a total coincidence, and so we are naturally inclined to think that Veysey had a scheme. This is what I called "inference against coincidence." There are serious doubts that this sort of inference is a good one, though it is very widespread and very intuitively appealing. It can be nicely applied to the Lucia de Berk case: so many deaths during Lucia's shifts at the children hospital cannot be a pure incidence, and so we are inclined to conclude that Lucia had something to do with those deaths. Similarly, in the Collins case, since it is very unlikely that a random couple would match a very eccentric description (i.e. woman with ponytail, man with mustache and beard, interracial couple driving a yellow convertible, etc.), we are inclined to think that the Collins were not a random couple at all, but rather, the guilty couple.
Note the difference between the Veysey and Lucia de Berk case, on the one hand, and the Collins case, on the other. In the former cases, the issue is "what happened?" but in the Collins case the issue is "who did the deed?" In both cases, however, the inference against coincidence can be used, and it is intuitively appealing.
In all these cases, the inference against coincidence is an instance of the inversion fallacy, i.e. the confusion of P(A|B) and P(B|A). Even if an event is extremely unlikely given the assumption that it happened by pure chance, it does NOT follow that the assumption that the event happened by chance should be rejected or that such an assumption is unlikely. For example, even if it is extremely unlikely that so many deaths occurred given the assumption that Lucia had nothing to do with them, it does not follow that (it is very likely that) Lucia had something to do with the deaths.
But how are the two probabilities P(A|B) and P(B|A) supposed to be related? There must be a relation between the two, no? How are we supposed to reason correctly with them? Bayes' theorem is the correct way to relate the two probabilities without incurring the inversion fallacy. This was the main topic of the class.
But before we turned to Bayes' theorem, I raised a philosophical question (which, as sometimes happens, might have obscured things rather than clarify them). Why should we follow the rules of probability and Bayes' theorem in the first place? There are two well-developed answers in the literature. First, if you want to maximize expected utility, you should assign probabilities in ways that conform with the probability axioms. (This, of courses, triggers the further question, why maximize expected utility in the first place?) The second answer is that if you do not follow the probability axioms, you will be willing to take bets in which you lose money no matter what. If you do not follow probably theory, you'll lose a lot of money. (The question here is, why would one want to take bets in the first place, especially if they involve the potential loss of lots of money?) There is a vast literature on that, and this is not the focus of this course, but I just wanted to make you aware of the question.
Next, we turned to Bayes. You can find the statement of Bayes' theorem in the handout, and the proof of it is mathematically straightforward. We looked at how the theorem can be applied to the Collins case. Let G abbreviate "the Collins are guilty" and let M abbreviate "the Collins match the description". We want to find out the probability that the Collins are guilty given that they match the description, i.e. P(G|M). To this end, Bayes' theorem requires us to assign a probability to G, M, M conditional on G, and M conditional on not-G. Simplifying things a bit, we can assign the following values:
- P(G)=1/n, where n is the number of potential suspects, maybe 6,000,000 people if we are considering the LA metropolitan area. Two clarifications here. First: P(G) is the probability that the Collins are guilty WITHOUT taking into account the fact that they match the description. (In the literature many refer to P(G) as the PRIOR probability of guilt; this is a bit misleading, but you get the idea.) Second: equating P(G) to 1/n is controversial because this implies that everybody has the same (prior) probability of guilt, which may not be so.
- P(M | G)=1. The assumption here is that the truly guilty couple does match the description D and that we cannot be mistaken whether or not the Collins match the description.
- P(M | not-G)= 1 in 12,000,000. This conditional probability is the probability that a random (non-guilty couple) would match. This probability is roughly equivalent to the estimated frequency of the description in question. In the Collins case, this estimated frequency was wrong, but here let's disregard that.
DNA cases have a structure that very much resembles the Collins case. There is a match, but the difference is that in DNA cases we are not dealing with facial descriptions but with genotypical descriptions. The match is between a suspect's genetic profile and the genetic profiles associated with the traces found at the crime scene. Second, the genotypical description (i.e. the genotype or DNA profile) is assigned a frequency, just like the description in the Collins case was assigned a frequency. So, you can see that the structure is the same, although in the DNA case the frequency of the DNA profile is more extreme (not 1 in 12,000,000, but possibly 1 in 6,000,000,000), and second, the estimated frequency of the DNA profile rests (hopefully!) on well-tested models and on justified statistical assumptions.
Next, we looked at some background materials about DNA and DNA evidence. You can find the slides I used here. There really are three important questions about DNA evidence. First, can DNA evidence be used to establish guilt? Second, how do we determine that there is a match between the suspect's DNA profile and the crime scene profile? Third, how is the frequency of the profile estimated? We had time to discuss the first two questions only.
We agreed that DNA evidence can place the defendant or the suspect at the crime scene. If there is a match between the crime scene genetic profile and the suspect's, then there is a link between the crime scene and the suspect. If we exclude (not uncommon) cases of framing and (less common) cases of DNA evidence fabrication, the link suggests that the suspect did visit the crime scene. Now, in order to establish the suspect's guilt, we need much more. While DNA evidence helps us determine "who was at the crime scene", we also need to reconstruct "what happened during the crime." We can do so by examining the crime scene and the crime traces found. By merging our answers to the question "who did it?" and "what happened?" we can use DNA evidence to establish guilt.
The next question is how a match is declared. On the handout you can see the pictures of DNA profiles that do match (at one locus) as opposed to profiles that do not match. It is clear from the pictures that a match is not something absolute, but simply a matter of degrees. The declaration of a match is not an all-or-nothing affair. So a question arises, which format of presentation should be preferred when a DNA expert present DNA evidence to the jurors or a judge? Is it better to say that the profiles match to a certain degree, or is it better to say that the profiles match or do not match? This is really a question about what the expert witness should do. Should he or she make the call about whether there is a match or not, or should this task be left to the jurors or the judge? We explored arguments in favor of both approaches. For one, the jurors might not be really qualified to understand what it means that two profiles match to a certain degree. For another, explicitly stating that the declaration of a match is not something absolute, but rather a matter of degrees, makes the jurors aware of the underlying uncertainty---and this is a good thing because in this way the jurors are not not fooled into thinking that the declaration of a match is a black-and-white affair.
There was no time to discuss DNA profile frequencies, how they are estimated, and whether they are dependable. We will do this next time, together with asking the question, are DNA profile unique?
Quantifying Standards of Proof
JAN
Prisoners in a yard
- Nesson (1979)
- Reading Guide - Week 4
- Handout - Week 4
-
This week was, again, entirely devoted to DNA evidence and the underlying statistical and probabilistic issues. Unfortunately, we could not cover the more general question of whether standards of proof can be quantified (Nesson's article). This topic is postponed to next week.
In the last couple of weeks we have seen different instances of the "inversion fallacy," i.e. the confusion of P(A|B) and P(B|A). We also saw that Bayes' theorem is a good way to see the relation between these two probabilities. Another equally widespread and equally dangerous fallacy is the "base rate fallacy." The following scenario can be used to illustrate the fallacy. Suppose in a small town there are two cab companies, Blue Company and Red Company. We know that all blue cabs belong to Blue Company, and that all red cabs belong to Red Company. One day an accident occurs, and a witness testifies that a blue cab was involved in the accident. We also know that the witness is reliable 80 percent of the time, i.e. he gets the color right 80 percent of the time. The question is, how probable is it that a blue cab was, in fact, involved in the accident? It is tempting to say "80 percent," but that would not be correct. We should also take into consideration the base rate of blue and red cabs in the small town. If there is an overwhelmingly large number of red cabs, and only very few blue cabs, the probability that it was a blue cab would still be quite low, despite the witness saying that it was a blue cab. Base rates are important and should not be neglected. The base rate fallacy consists precisely in ignoring base rates.
And, once again, Bayes' theorem lets us see why base rates are important. Let B abbreviate the proposition that the taxi involved in the accident was blue, and let Wb abbreviate the proposition that the witness testifies that the taxi was blue. What we want to know is P(B|Wb), i.e. the probability that the taxi was blue given that the witness says it was blue. According to Bayes' theorem, the value of P(B|Wb) depends crucially on the value of P(B). Now, P(B) is the probability that the taxi was blue WITHOUT taking into account the witness testimony about the taxi's color, so P(B) is nothing other than the base rate. If we apply Bayes' theorem, we can see that the higher P(B) the higher P(B|Wb), and the lower P(B) the lower P(B|Wb). The base rate probability P(B), then, does affect P(B|Wb) quite dramatically and cannot be ignored. A more detailed explanation is available here.We can think of the base rate fallacy in the context of DNA evidence as well. Suppose we want to know the value of P(G|M), i.e. the probability that the defendant is guilty given a DNA match. According to Bayes' theorem, this probability depends crucially on the value of P(G), i.e. the probability of guilty WITHOUT taking into account the DNA match. Once again, P(G) represents the base rate probability and it does affect dramatically the value of P(G|M).
So far we have worked with one formulation of Bayes' theorem, i.e. P(A|B)= [P(B|A)/P(B)]xP(A). There is, however, another formulation in terms of odds, as follows:
P(A|B)/P(P(not-A/B)=[P(B|A)/P(B|not-A)]x[P(A)/P(not-A)].
The first factor, [P(B|A)/P(B|not-A)], is typically called the "likelihood ratio" and the second factor, [P(A)/P(not-A)], is typically called the "base rate ratio" or the "prior odds ratio." Again, the value of P(A) affects the value of P(A|B) significantly.
We can now apply this second formulation of Bayes' theorem to DNA evidence. We want to know the probability P(G|M), and by Bayes' theorem, we know that
P(G|M)/P(P(not-G|M)=[P(M|G)/P(M|not-G)]x[P(G)/P(not-G)].
Let's make the following value assignments:
- P(G)=1/n, where n is the number of potential suspects. Now, equating P(G) to 1/n is controversial for a number of reasons, e.g. because it implies that everybody has the same (base rate) probability of guilt, which may not be so, but also because it presupposes that there must be someone who is guilty in the first place, which may not be so.
- P(M | G)=1. The assumption here is that the truly guilty defendant must turn out to be have a matching DNA profile. This is also a questionable assumption. For example, it might happen that even though an individual is the guilty defendant, testing him or her would not return a match. This is what is called a "false negative" (i.e. the failure to report a match, while the individual, in fact, does match). So, P(M| G)<1.
- P(M | not-G)= the frequency of the DNA profile. This conditional probability is the probability that a random (non-guilty defendant) would match. This probability is roughly equivalent to the estimated frequency of the DNA profile in question. But again, this assumption is also questionable, because a test might mistakenly report a match for a non-guilty defendant who does not match; this is called a "false positive."
Instead of trying to estimate directly the probability of G, it is better to aim at a more modest claim, e.g. "source". Instead of looking at P(G|M), we can consider P(S|M), where S abbreviates "the defendant is the source of the DNA traces found at the crime scene." Note that there is a difference between "source" and "guilt". For someone might be the source of the DNA traces at the crime scene without being guilty. One might have left the traces without being involved in the crime, or might have been framed, or might have left certain traces during the crime accidentally, etc. If we focus on S, instead of G, we get:
P(S|M)/P(P(not-S|M)=[P(M|S)/P(M|not-S)]x[P(S)/P(not-S)].
Let's make the following value assignments:
- P(S)=1/n, where n is the number of potential suspects. Now, equating P(S) to 1/n is controversial for reasons that are roughly similar to why P(G)=1/n is problematic. For example, not everybody need to have the same (base rate) probability of being the source.
- P(M | S)=1. Here the issue of false negatives returns, so P(M| S)<1.
- P(M | not-S)= the frequency of the DNA profile. Again, this assumption is questionable, because a test might mistakenly report a match for a defendant who does not match, so the issue of false positives returns here.
There is a mixed moral to draw from our discussion so far. For one, Bayes' theorem is a tremendously useful tool to understand and think through a problem. Bayes' theorem can help us identify fallacies, such as the inversion fallacy and the base rate fallacy. In this sense, Bayes' theorem is very useful. On the other hand, it should be quite clear that it is hard to assign precise numbers. To be sure, we can assign numbers to P(G), P(S), P(M|G), etc, but we must always rely on assumptions. And often those assumptions are not clear or can be overlooked. Most worrying is the fact that Bayes' theorem does not really help us identify those assumptions; we need to identify them by thinking carefully. So, why should we assign numbers and use Bayes' theorem in the first place? Does it really help?
A second issue we considered was whether DNA profiles can be said to be unique. This question is misleading but it comes up in criminal trials often, so it is worth addressing. For example, we read a quotation from the OJ Simpson trial transcript along the following lines: the DNA profile has a frequency of 1 in 50 billion; the are only 6 billion people on earth; hence, the DNA profile must be unique. This is often called the "uniqueness fallacy," i.e. the mistaken conviction that if the denominator in the frequency exceeds the total earth population, the DNA profile can be said to be unique. This is a mistake for a number of reasons. Here are a few. There is a difference between expected and actual frequency. It is true that if a DNA profile has a frequency of 1 in 50 billion, we EXPECT to find 1 such profile every 50 billion people. Still, this expectation need not be the same as the ACTUAL frequency. Also, there could be identical twins or brothers, and therefore the frequency need to be taken with a grain of salt. And finally, we should never forget that even if the DNA profile were, in fact, unique, we would still have no conclusive answer to the question of whether or not the defendant is guilty.
I then brought up the controversy about the Arizona database matches. I mentioned this because it might seem to cast doubt on the empirical adequacy of the estimated frequencies of DNA profiles. When it was tested, the Arizona database contained roughly 67,000 entries, and several partial matches (i.e. matches at only 9 out of 12 or more loci) were found. Such matches were found for a (9 loci) DNA profile with an estimated frequency of 1 in 700 million. So, just to be clear, although the profile was expected to occur once every 700 million people, the profile in question showed up multiple times in a database containing only 67,00 entries. This seems pretty surprising, no? Indeed, it is tempting to question the empirical adequacy of the estimated frequency. Maybe, one could say, the frequency should not be as low as 1 in 700 million, but this would be a mistake.
The surprise might be in part explained by assuming that some DNA profiles were duplicates or that the same DNA profile was entered twice under different names in the database. Still, let us put these explanations aside. There are also mathematical and combinatorial reasons that can explain why so many matches were found. The basic point to appreciate is that one thing is to search for a match given a SPECIFIC genetic profile. The number of possibilities to be considered in this case is the number of entries in the database. But another thing is to search for a match given ANY genetic profile in the database. The number of possibilities here becomes much larger, because one is considering all possible pairs, so the possibilities are NxN, with N the number of entries in the database. A more detailed explanation is provided by David Kaye here (section II, part A and B).
(The issue is connected to a well-known paradox, called the Birthday Paradox. For combinatorial reasons, the chance that ANY two people share the same birthday in a group with only 23 people is as high as 50 percent. And this is the case even though the probability that one's birthday falls on a particular day is as low as 1 in 365 days. One should not confuse two probabilities: the probability that ANY two people share their birthday, with the probability that someone else shares your SPECIFIC birthday. The former probability is higher than the latter. For more on the Birthday Paradox, see here. )
The third and final question we considered was about the cold hit debate. In short, the debate is that the NRC thinks that in cold hit cases a genetic match is less significant compared to standard cases, whereas Bayesian statisticians such as Peter Donnelly think that there is no difference in significance between standard and cold hit cases. Who is right? I have written a note in which I sketch a way to resolve the controversy; it is available here.
Unfortunately, there was no time to discuss Nesson's article on the quantification of the criminal standard of proof. We will discuss it next week.
FEB
Buses and gunshots
- Smith v. Rapid Transit, Inc. (1945)
- Thomson (1986)
- Reading Guide - Week 5
- Handout - Week 5
-
We reviewed four fallacies we can commit in reasoning with statistics/probability in criminal trials (esp. with DNA evidence and its underlying statistics). These are the inversion fallacy, base rate fallacy, uniqueness fallacy, and database fallacy. The fallacies are illustrated below.
The inversion fallacy goes like this: since there is a low probability that a random individual would have a DNA that matches, and since the suspect does have a DNA that matches, there is a low probability that the suspect is a random individual. This confuses P(Match| Random Individual) and P(Random Individual| Match).
The base rate fallacy goes like this: since the test is highly reliable, there is a high probability that the result of the test is correct. This neglects the base rate probability of the event (match, disease, etc.) which the test is meant to detect.
The uniqueness fallacy goes like this: since the DNA profile has a frequency of 1 in 50 billion, and the population of the earth is only 6 billion, the DNA profile must be unique.
The database fallacy goes like this: since several individuals with the same DNA profile were found in a relatively small database (e.g. 60,000 entries), it must be false that the DNA profile has a low frequency (e.g. 1 in 100 million). This reasoning is faulty as illustrated by the well-known birthday paradox. Take 30 people in a room. Then, the probability that NO pair of people with the same birthdays is found equals [365 x 365-1 x 365-2 x.... x 365-30+1]/[365^30], which is approximately 0.3. So, 0.7 is the probability that AT LEAST one pair of people with same birthday is found. Note that even if the probability of a birthday falling on one specific day is as low as 1 in 365, you only need 30 people to have at least a 0.7 chance of finding a pair of people with the same birthday. So even if the frequency of a certain profile might be relatively low, it is enough to have a relatively small database to find at least two entries with the same DNA profile.
We also looked at another alleged fallacy. In the Amanda Knox case, the appellate judge refused to order a DNA retest, on the conviction that doing the same test twice would not make much of a difference. But the authors of a NY Times article on the case claim that performing the DNA test twice could potentially unravel the truth about the case. Their reasoning is that if you find a match twice, that makes the result much more robust than if you find it only once, so the judge would have committed a mathematically fallacy here. Crucially, this argument is true if the two outcomes of the test are independent of one another. But maybe there are reasons to think that both outcomes would be biased in one direction (e.g. because the available DNA traces were too small to be analyzed, so a second test would not help). David Kaye discusses this issue in a blog post here.
Now, in light of all the potential fallacies we might commit as we reason with probabilities, it is tempting to conclude that we should do away with numbers, statistics and probability in the courtroom altogether. If we are so prone to error, why bother with probabilities? Arguably, there might be a way to reason precisely and rigorously in the courtroom without using numbers. Here is a well-known quotation: ''How often have I said to you that when you have eliminated the impossible whatever remains, HOWEVER IMPROBABLE, must be the truth? We know that he did not come through the door, the window, or the chimney. We also know that he could not have been concealed in the room, as there is no concealment possible. Whence, then, did he come?'' Conan Doyle, The Sign of Four (1890). The quotation describes a way to do forensic and legal reasoning without using probabilities. The idea is that such reasoning proceeds by ruling out alternative possibilities or alternative reconstructions of what happened. The result is that "whatever remains, however improbable, must be the truth." This also raises new questions, however. What does it really mean to rule out certain alternative possibilities? Isn't the process of ruling out alternative possibilities also a probabilistic process? And what if we have failed to consider (or imagine) certain possibilities? In that case, what remains will not be the truth...
So, in fact, we might have to deal with numbers, probabilities, and statistics in the courtroom, whether we like it or not. Moreover, the fact that DNA evidence comes with numbers attached is an example of this inevitability. And it is plausible to think that in the future more types of evidence will come with numbers attached (e.g. glass evidence, fiber evidence, trace evidence in general). Legal and forensic reasoning appears to be a mixture of probabilistic, numerical reasoning, along with non-numerical, qualitative reasoning of the kind Conan Doyle describes. But how can the two be integrated? This is a very pressing question---a question that has not yet received a clear answer.
In the second part of the class we tackled a more abstract question. So far we focused on how we reason (correctly and incorrectly!) with probabilities, with an emphasis on DNA evidence. Let us leave these details behind! The thesis now on the table is LEGAL PROBABILISM, which consists of two sub-claims (at least as far as I interpret it). First, the Quantification Claim (i.e. the claim that we can assign a probability to the defendant's guilt), and second, the Threshold Claim (i.e. the claim that if the probability of the defendant's guilt reaches an appropriately high threshold value, then a conviction can be issued). Both claims, and especially the first, are possible once a high degree of idealization is granted; this means that even if we cannot really quantify one's probability of guilt, we may idealistically suppose that we can.
Nesson argues that the "probabilism approach"---and more generally, the quantification of the criminal standard of proof---undermines the role of the jury. The jury deliberates in secret and its task is to resolve ambiguities and complications in the case. If the probability of guilt were to be quantified and made public, anyone could challenge and criticize the jury's decision. For whenever guilt is explicitly quantified and an openly numerical threshold is adopted, the decision of the jurors can be immediately subject to public scrutiny. It then becomes too easy to criticize a verdict. A non-mathematical standard of proof, instead, leaves the needed ambiguity. So, Nesson thinks that legal probabilism (but not just legal probabilism as a theory, but in case it were implemented in the courtroom) would undermine the jury and the authority of verdicts because verdicts would be become to easily subject to scrutiny.
The obvious objection here is that this is a cynical position to take, but at least, Nesson is quite honest! And further, Nesson has the merit of focusing on the question ``what do we want the criminal standard of proof and the criminal justice system to achieve?'' Depending on how we answer this question, we can have reasons for dismissing or endorsing legal probabilism.
(One point that Nesson makes is that while legal probabilism might be conducive to the goal of truth, it is not conducive to the goal of "authority of verdict." Now, this claims presupposes that legal probabilism is conducive to the goal of truth. I suggested in class that this claim is wrong. Here is my general point. If we set the threshold for a conviction to a high probability of guilt, this has the effect of lowering the rate of wrongful convictions at the cost of increasing the rate of wrongful acquittals (at least compared to a lower threshold). Overall, a high probability threshold causes the justice system to commit A LOT of errors, especially a lot of wrongful acquittals. So, it does not seem to serve the goal of truth, if by 'truth' we mean 'striving to minimize errors.' Rather, setting a high probability threshold merely serves the goal of distributing errors in a way that is economically efficient and socially acceptable.)
In a later article, Nesson argues that the logic of legal proof requires to focus on the facts, on what happened or not happened, and not on whether or not the evidence strongly or weakly supports a certain reconstruction of what happened. The judgment should be a judgment about the facts, not a judgment about the evidence (or about whether the evidence supports certain facts with a sufficiently high probability). Note the difference between the verdict ``not guilty'' and the verdict ``not proven guilty''. There seems to be a preference of the criminal justice in portraying itself as being about facts, not about whether the evidence supports such facts. What social and political function does this posture or ``illusion'' promote? It may have to do---once more---with shielding the justice system from criticism.
We finally turned to Thomson's article. We looked at the blue bus hypothetical scenario. The scenario goes like this: an accident occurs in which a pedestrian is injured by a bus; two bus companies are operating buses in the area at the time of the accident; one company has significantly more buses in operation than the other. The suggestion here is that the company operating more buses is statistically more likely to be responsible for the accident, because one of its buses is statistically more likely to be the bus involved in the accident.This scenario brings something new to the table because it is a civil case, and not a criminal case any longer. Now, Thomson has the intuition that a finding of liability against the company operating more buses would not be justified. Is this intuition correct? We outlined some arguments in support of Thomson's view. First, he mere statistical chances do not establish that the company with more buses should be responsible. (This is essentially the position of the Supreme Court of Massachusetts in Smith v. Rapid Transit.) Second, if the company with more buses were found liable, this would be an incentive against running companies with more buses. Operating more buses, after all, cannot be a ground for liability. Third, if the company with more buses were found liable, in subsequent cases, people will sue companies whose bus routes are in the vicinity of an accident.
On the other hand, there are also good reasons to think that in civil cases the matter is more complicated and nuanced, or at least, very different from a criminal case. In a civil case---arguably---we are not concerned with finding the truth about what happened, but rather, we want to reach a solution that is economically and socially efficient. So, perhaps, it is better to make the bigger company pay, or pay in proportion to how many buses it operates. We should also consider that we need to give some form of compensation to the victim; it does not seem just to leave the victim empty handed simply because the mere statistical chances are not enough to establish the involvement of one company or another in the accident. We will look at the concerns for an efficient and fair apportionment of damages next time while reading the Sindell decision.
There was no time to discuss Thomson's argument in detail. In the last few minutes, I summarized her proposal. For one, she holds that the evidence supporting a legal judgment should be individualized, specific to the defendant or to what happened. She thinks that statistics are not individualized. In particular, her account of individualized evidence is evidence that is causally connected (in the appropriate way) with the event of the crime or with the wrongdoing. Statistical, often, do not satisfy this "causality requirement." An open question here is, why should the evidence be causally connected? Why is that something we should value?
The second point that Thomson makes is that if the bigger company were found liable, and if the company was in fact involved in the accident, the judgment would be correct only as a matter of luck or accident. Thomson thinks that statistical evidence cannot offer an "guarantee" for the truth of the conclusion we may draw on its basis. So, statistical evidence cannot shield us from "epistemic luck." But why is that? And does individualized evidence really shield us from epistemic luck?We will take up these questions next time.
FEB
Civil liability
- Schmalbeck (1986)
- Sindell v. Abbott Lab. (1980)
- Reading Guide - Week 6
- Handout - Week 6
-
We began by reading an excerpt from the book "Discipline and Punish" by the French philosopher Michel Foucault . The excerpt illustrates how the connection between mathematics and criminal justice dates back to the Middle Ages and its system of "penal arithmetic." Different degrees of proof were used (i.e. clues, half-proofs, and full-proofs). The different degrees of proof were proportionally related to degrees in the severity of punishment, e.g. a defendant could receive the death penalty only if there was a full-proof of his guilt. Also, procedural rules regulated how different proofs could be added, so that two half-proofs would give a full-proof, and several clues together could amount to a half-proof but never amounted to a full-proof. A noteworthy feature of this system is that judgments were not dualistic, as it were: defendants were not found simply guilty or simply innocent, as is the case today. Rather, defendants were found "little guilty," 'half guilty," or "fully guilty." And these judgments were proportional to the degree of proof available. While such a system was elegant and nicely organized, one possible danger was that when a defendant was declared "little guilty," he could be mildly punished. Mild punishment could mean that the defendant was subject to a small degree of torture (and through torture, often, a confession was elicited, which would amount to full-proof.)
The piece by Foucault raises many questions about the history of the legal system. There was no time to address these questions. But the point of reading Foucault was to emphasize that the attempt---or should we say, the temptation?---to "mathematize the trial" is not something new or recent. It has always been there.
The next topic was Thomson's article; we could not discuss it in full last time. Thomson makes two points. The FIRST point is that the evidence in a trial should be individualized to the defendant (in a criminal case) or to whoever is alleged to have caused the harm (in a tort case). How does she understand the notion of individualized or specific evidence? Here is her proposal: evidence counts as individualized whenever it is causally connected (in the appropriate way) with the event of the crime (or with the facts disputed at trial). I insisted that the causal connection here is between the evidence and the event of the crime (and this is something that many neglected to say in their response papers). The SECOND point---which we could not discuss (still!)---is that the causal connection matters because it shields the judgment of the fact-finders from what we might call "epistemic luck." You can find a discussion of this notion here.
Thomson's first point triggered a lively discussion. Here are some of the open questions (along with some tentative suggestions):
- Is DNA evidence casually connected with the event of the crime? Does DNA evidence count as individualized according to Thomson? It seems that DNA evidence counts as individualized because it consists of a match between the genetic traces found at the crime and a suspect. The genetic traces, after all, should be causally connected to the event of the crime because their presence at the crime scene, presumably, was triggered---in some causal way---by the occurrence of the crime. (We should be careful here, though. Traces that are causally connected with the crime need not point to the guilt of the individual who left them: the traces might have been left *during* the crime but in ways that have nothing to do with one's guilty behavior.) On the other hand, DNA evidence also consist of statistics, namely the estimated frequency of the DNA profile which is said to math. Without such statistics, the match itself is worthless. And since statistics aren't causally connected with the crime, it seems that DNA evidence is also not causally connected with the crime. DNA evidence is causally connected because of its "match component" but it also not causally connected because of its "statistics component."
- How does DNA evidence differ from the Bus Hypothetical? We might read the evidence available in the Bus Hypothetical as consisting of two items (in ways that are analogous to the DNA evidence case). First, we have a (sort of) "match" in the form of a witness or some tire traces showing that it was a bus which was involved in the accident. Such "match" would meet Thomson's causal requirement. Second, we have the statistics that allow us to identify which of the two bus companies is more likely to have been involved in the accident. In the Bus Hypothetical, then, we can find both a match as well as the statistics, and if so, the difference between this case and the DNA evidence case becomes unclear. One thing to note here, however, is that the statistics play different "inferential roles" in the two cases. In the Bus Hypothetical, the statistics allow us to identify which company is more likely to have been involved in the accident. The match itself does not tie one company to the accident. In the DNA evidence case, instead, the statistics simply give us a sense of the significance of the match, whereas the match itself already ties one specific suspect to the crime.
- Can't we say that statistical evidence is itself causally connected? And conversely, isn't it the case that all evidence is statistical, even eyewitness evidence? So far the assumption has been that we can make sense of causality without appealing to statistical correlations, but maybe we cannot. This is a hotly debated philosophical question. Maybe a causal relation between A and B is just a complicated form of statistical and probabilistic correlation between A and B. If so, the disproportionate number of blue buses might have "caused"---in some loose sense of causality---the fact that a blue bus was involved in the accident. This line of argument puts pressure on Thomson's causality point. Another way to resist Thomson's point is to argue that all evidence is statistical. For instance, we might argue that our standard example of pieces of evidence that are causally connected with the event of the crime (i.e. eyewitness testimony and trace evidence) aren't causally connected.
- Isn't it the case that the only way we have to know about the causal connection is through probabilistic means? Thomson thinks that evidence should be causally connected to the crime, but of course, we cannot really know whether the evidence is, in fact, causally connected. A witness, presumably, saw the crime, but maybe he did not. Certain traces, presumably, were left during the crime, but maybe they were not. So, it seems, the only way we have to establish the existence of a causal link between evidence and crime is indirectly, by making assumptions about what most likely happened. We can infer the existence of a causal link between evidence and crime only probabilistically. This observation might put some pressure on Thomson insofar as the causal relation is something that is ultimately inaccessible to us, at least, it is inaccessible if we do not already know the truth of the case.
We decided not to discuss Thomson's second point about epistemic luck in the interest of time. So, after the break, we talked about the expected utility model and the Sindell decision.
The application of the expected utility model to the trial context is described in the handout. I wanted to discuss the expected utility model because it highlights another way by which probability can be used to theorize and understand the trial. So far we have used probability to quantify guilt. We were aiming to come up with a value for the probability of guilt or a value for propositions that had something to do with guilt (e.g. source). This is, of course, very difficult, if not impossible, but our long discussions about DNA evidence and Bayes' theorem were headed in that direction. I suggest that we call this use of probability the "quantification of error."
There is a second use of probability, which we might call the "managing of error." And this is where the expect utility model comes in. The expected utility model gives us a recipe for taking decisions. The main idea is that decisions should be taken in order that expected utility be maximized or expected losses minimized. (Expected utility is a notion that blends utility and probability.) This is where economic and policy considerations come in, as well. On the managing-of-error perspective, the concern is to arrive at trial decisions that are socially optimal and economically efficient. (See a note on the law and economics approach here.) These sort of concerns are at work also behind in the Sindell decision, although the expected utility model is not explicitly endorsed in the text of the decision.
Finally, we discussed the Sindell decision. The standard doctrine of civil liability requires that the plaintiff should establish "individualized causation". That is, the plaintiff should establish that the defendant caused harm to the plaintiff in the specific instance under consideration. In an age of mass production, however, this is often impossible. If a manufacturer markets a product, it might be difficult to establish---in a specific case for a specific individual---that such a product caused harm, although it might be easier establish (on the basis of aggregate statistics) that the product posed a higher risk to consumers.
Before Sindell, there was another theory that could be used instead of the traditional theory of civil liability. This theory is known as "alternative liability theory." See the case Summers v. Tice (1948). The theory of alternative liability states that when a plaintiff cannot establish which among two or more defendants caused harm, the defendants are jointly liable UNLESS they can prove otherwise AND PROVIDED it is clear that all defendants have been negligent. In the Summers case, for instance, both defendants shot in the direction of plaintiff during a hunting expedition. They did not exercise enough care; they were therefore both negligent.
Sindell is a modification of the doctrine of alternative liability. It articulates for the first time the "market share liability doctrine." The basic idea is that each manufacturer should reimburse plaintiff in proportion to its market share. Why apply this doctrine? The issue in Sindell was that although it was clear that a certain product did cause harm to the plaintiff, it was impossible to identify the product's manufacturer. There were a number of possible manufacturers, each sharing a different quota of the market. The doctrine of market share liability is an attempt to overcome the difficulty in establishing individualized causation in cases such as Sindell. Just like in Summers, we also have a shifting of the burden of proof. That is, liability is apportioned in proportion to the manufacturer's market share UNLESS one of the manufacturer can prove they did not cause harm at all. A more detailed description of the differences between the Summers theory and the Sindell theory can be found in the handout.
Two points emerged from our discussion. First, we should locate the Sindell decision in the wider context of class actions and mass litigation. Sindell is not a class action case, but we can see why the individualized causation requirement that is proper of the traditional theory of civil liability is under pressure in class action cases. It is often impossible and too costly to establish that, in each single case, a certain product caused harm. In class action cases, plaintiffs form a group (a class, that is). If plaintiffs can establish that the harm was caused in some instances, the entire class of plaintiffs is entitled to recover damages. This raises the question, what criteria determine when a group of plaintiffs count as a class? What degree of similarity among the different plaintiff is required? In the class action case Wall-Mart v. Dukes (2011), for instance, that US Supreme Court found that the class was not certifiable because the criteria to group the plaintiffs together were not met.
Second, the Sindell doctrine was based on only one 1978 academic article "DES and a Proposed Theory of Enterprise Liability" by Naomi Sheiner which appeared in the Fordham Law Review (available here). This made us question the soundness and adequacy of the decision. If the decision was meant to achieve a socially optimal outcome or to regulate trial proceedings in a better way, are we sure the decision was effective in doing so? Isn't one academic only article meager evidence in support of the decision? What if the theory of market share liability could have negative effects? Did the Court consider them? This raises the question of what standards courts use to reach decisions, especially if their decisions affect litigations on large scale. However we think of this issue, the Sindell decision was a groundbreaking and highly innovative decision. But was it the right decision?
FEB
Psychological findings
- Wells (1992)
- Reading Guide - Week 7
- Handout - Week 7
-
We began by discussing the Branion appellate case (available here).
Earlier in the course we encountered different strategies for handling the inherent uncertainty in legal decision-making. One strategy consists in imposing a very demanding standard of proof, i.e. the criminal standard of proof beyond a reasonable doubt. The rationale for a demanding standard is that wrongful convictions should be avoided as much as it is reasonably possible.
Second, we saw that in civil cases the standard of proof is lower. And further, according to the Sindell doctrine -- also know as ``market share liability doctrine'' -- information about the percentage of a company's market share can be sufficient to shift the burden of proof from plaintiff to defendant. This strategy for handling uncertainty takes very seriously the need to compensate plaintiffs without leaving them empty handed. Here the focus is not so much on reconstructing ``what happened'' (as we would do in a criminal case), but rather, on achieving a socially and economically optimal outcome such that neither the defendant nor the plaintiff bears unfair burdens.
In the Branion appellate decision we encountered a third strategy for handling uncertainty. This strategy does not pertain to criminal or civil cases; it pertains to appellate decisions. The standard for appellate review is what we might call the ``clearly erroneous standard.'' For instance, the appellate court invalidates a jury verdict in a criminal case only if it is clear that the jury reached a verdict which no reasonable person could have possibly reached. The standard for appellate review, then, is not whether a reasonable juror WOULD be persuaded beyond a reasonable doubt about the defendant's guilt, but whether the juror COULD be persuaded.
We discussed whether the ``clearly erroneous standard'' for appellate review is well-justified. It is very different from (almost the opposite of) the criminal standard of proof beyond a reasonable doubt. Whereas the criminal standard seeks to protect the accused as much as possible, the standard for appellate review seeks to protect the jurors' decision to convict as much as possible. The former seeks to avoid convictions, while the latter seeks to avoid the reversal of convictions. We might say that the two standards balance one another.
Next, we turned to some psychology. I reiterated the well-known fact that eyewitness evidence is very unreliable. Elizabeth Loftus, who performed pioneering experiments, showed how feeding false information can easily change our recollection of past events. We watched a short video describing one of her experiments (available here). We also read an exchange between a witness and a defense lawyer (available here). The exchange shows quite clearly how a mistaken identification can occur: the witness misidentifies the perpetrator by mistaking a familiar face with the face of the perpetrator.
Fingerprint evidence -- which used to be considered the gold standard of criminal evidence -- is also unreliable. First, we have no scientific data about whether fingerprints are unique or not. Nor do we have any statistical estimate of how rarely a fingerprint profile occurs in a sample population. In contrast, we do have such estimates for DNA profiles. Second, experiments have shown that the same expert might testify that one pair of prints match, while testifying that the same prints do not match at a later point. What changed the expert's judgment? Apparently, if the expert is exposed to different contextual information about the case on two separate occasions, he might conclude that the prints match on one occasion and conclude that they do not match on another occasion. This shows that fingerprint identification is highly subjective and arbitrary.
Finally, DNA evidence -- considered the most powerful form of evidence currently available -- is not immune from problems either. In the handout, you find some of the problems we discussed earlier in the class.
But given that three of the most important forms of criminal evidence have shortcomings, a question suggests itself. How should we handle these forms of evidence? Clearly, we cannot ban them from criminal trials, because if we did that, we would be left with little or no evidence to prosecute defendants. So, a careful examination of how the evidence should be handled, weighed, and scrutinized is of the utmost important. Note that the application of probability theory here can offer us a method to assess, weigh, and scrutinize the probative value of inherently fallible evidence. Whether this application of probability theory is realistic or feasible is a question that often came up during the course.
Another question that emerges at this point is as follows. Since three of the most important forms of criminal evidence are inherently fallible, aren't we running the risk of convicting too many innocent? This is particularly worrying if convictions are based on eyewitness and fingerprint evidence. The latter two have been the most widespread causes of wrongful convictions, at least according to data from the Innocence Project. This is a worry that many legal commentators and scholars share today. And this worry often turns into the imperative that we should do better to protect the innocent. But should we really? As the provocative quotation from the Larry Laudan suggests (see footnote in the handout), even if thousands of innocent defendants had been convicted in the last thirty years, this would still be a relatively low wrongful conviction rate, because million of people are convicted and most of them are (likely to be?) factually guilty. This argument is meant to be a provocation. Now, the argument has some force, but it mostly rests on speculating how many wrongful convictions occurred. After all, the number of wrongful convictions in the last thirty years might be higher than ten thousands. Who knows? We cannot estimate what such a number could possibly be.
After the break, each of you presented her or his own iteration of Garry Wells' experiments. Wells' results seemed to be confirmed, although a couple of worries emerged.
First, some subjects were reluctant to find defendants liable on the basis of mere statistics; this agrees with Wells' results. At the same time, some subjects showed reluctance in reaching a conclusion on the basis of non-statistical evidence, e.g. expert or eyewitness evidence. This poses a challenge for Wells' result. The reason for the reluctance, in many cases, seemed to be that the expert's or witness's track record was thought to be ``probabilistically weak.'' In other words, knowing that the expert was, say, right 80 percent of the time made some subjects uneasy if they were to find the defendant liable.
Second, subjects often seemed to make decisions and think in terms of criminal trials, not civil trials. They often said that the statistics were not enough to "convict.''
So a natural explanation here is that the subjects found the statistics wanting because they applied a very demanding standard of proof. This would explain why they were unwilling to ``convict'' on the basis of the statistics alone, but it would also explain why they were unwilling to ``convict'' on the basis of a non-statistical testimony. Indeed, this is a working hypothesis which needs testing. And there may well be other alternative explanations. I encouraged those of you who enjoyed Wells' experiments to design and conduct your own experiment for the final assignment.
Tax law, Profiling, and Discrimination
FEB
Probability in Tax Law
- Lawsky (2009)
- Kaplow (2008) [optional]
- Reading Guide - Week 8
-
Prof. Sarah Lawsky from UC Irvine gave a guest lecture today on tax law and probability.
The law and economics movement has been extremely influential in the legal academy, presumably because of its simplicity, elegance, and mathematical appeal. As SL put it, people thought that ``if it's mathematical, it must be right!'' In tax law scholarship, a crucial question concerns how to formulate a theory of penalties. The law and economics approach offers an elegant answer. The expected penalty should equal the expected harm, i.e. expected penalty=probability x harm to society. The harm to society is what results from an incorrect tax position. The probability in question is the probability that the tax position is not correct.
Why are we assigning a probability to whether a tax position is correct or not? Aren't tax positions either correct or incorrect? No. The correctness of a tax position depends on what a court decides. Roughly put, if a court decides that a tax position is correct, the position is correct, or else the position is not correct. (Of course, the decision is not definitive insofar as it can be challenged on appeal.) SL emphasized that the probability that a tax position is correct is the probability that the tax position would survive challenges in court. Most tax positions are never challenged in court, but that does not imply that most tax positions are correct. To assess the probability that a tax position is correct, consider the hypothetical case in which the tax position is in fact challenged in court. Now ask: how likely is it that the court will uphold the tax position? The answer to this question gives you the probability that the tax position is correct.
Tax lawyers are routinely asked to give numerical, probabilistic estimates regarding whether a certain tax position is correct. Their clients need to know how likely it is that a certain tax position would survive challenge in court. But how do tax lawyers know the probability that a tax position is correct? And what does this probability mean?
Here is one possible answer. The probability that a certain tax position is correct is a frequency. In other words, the probability that a certain tax position is correct expresses how often courts have upheld said tax position. But which courts are we considering here? Only the courts that have examined similar tax positions? And if so, when are tax positions similar to one another? The frequency answer is replete with difficulties which go under the heading ``reference class problem.'' That is, it is hard to identify the appropriate class relative to which we can determine the frequency-probability. Is the appropriate reference class the class of all court decisions that have been made? Is it the class of decisions being made by a certain court? Is it the class of all decisions being made by a certain court in a certain type of cases? Depending on the reference class, the resulting frequency (and thus the resulting probability) will be different. But what is the correct reference class, then? And so, what is the correct probability?
SL thinks that the probability that a tax position is correct is best understood as a subjective estimate, and not as an objective frequency. SL holds that the correctness of a tax position is a matter of uncertainty rather than risk.
The distinction between risk and uncertainty is roughly this. We are in a situation of uncertainty relative to the occurrence of an event whenever the event might occur or not, and also, whenever the probability of the event is unknown. In contrast, we are in a situation of risk whenever the event might occur or not, and also, whenever the probability of the event is known. In short, uncertainty has to do with contingent events whose probability is unknown, while risk has to do with contingent events whose probability is known. For instance, as we throw a fair coin, we do not know whether it will come up heads or tails, but we do know that it will come up heads (or tails) with a 1/2 probability. This is a situation of risk. Contrast this situation with a possibly forthcoming snowstorm about which we have no information whatsoever. The snowstorm might happen or not in the immediate future, but its probability is unknown given the little information available. This is a situation of uncertainty.
The distinction between risk and uncertainty, SL suggested, might ultimately be an artificial one. Risk and uncertainty can be best understood as two extremes on a continuum. If we have nearly no information about an event which may or may not occur, such an event would be uncertain. As we gain more information about the event in question, we move from uncertainty to risk. The line between risk and uncertainty, then, is a fuzzy one.
What about tax law? SL thinks that the probability that a tax position is correct is more a matter of uncertainty than a matter of risk. Or at best, if we were to assign a probability, SL argues, this probability should be understood as a subjective estimate, not as an objective frequency. What is a subjective estimate? To this end, SL introduced a betting analogy. Suppose I bet that the coin will come up heads. The bet pays me one dollar if the coins comes up heads, or else I will lose 0.75 dollars if the coin comes up tails. Given that I am willing to enter such a bet, it looks as though my subjective estimate of the probability of heads is 0.75. This is the betting interpretation of probability.
This interpretation is not immune from problems because it presupposes that we are risk neutral or that we do not dislike betting. In a more subtle formulation, dollar amounts are replaced with units of utility. (By using utility units, we can imagine different people associated with different utility functions. Some might consider winning 10 million dollars as having a high utility, but very wealthy individuals might consider it as having no utility at all.) Now, suppose I am willing to partake in a bet that pays me one unit of utility if the coin comes up heads, or else I lose 0.75 units of utility if the coin comes up tails. My betting behavior indicates that my subjective estimate of the probability that the coin will come up head is 0.75.
The betting interpretation of probability reduces probability to a subjective estimate. In the end, however, such an estimate rests on information about the event whose probability is being estimated. It is hard to know the numerical probability, and in the tax case, it is particularly hard to collect information about how likely it is that a court will uphold a certain tax position. Further, tax lawyers do not seem to be qualified to come with such numerical estimates at all. And yet, they are required to do so.
Perhaps, SL suggested, we should do away with numerical probabilities altogether, and replace them with qualitative language (as was more common before the rise of the law and economics movement). If we do so, however, the law and economics approach would lose its ground.
MAR
Profiling and Drug trafficking
- Colyvan et al. (2001)
- United States v. Shonubi (1995)
- Reading Guide - Week 9
- Handout - Week 9
-
In the first part of the class, Bart Verheij -- a professor of Law & Artificial Intelligence at the University of Groningen and a fellow at the
Stanford Law School within the CODEX project -- gave a guest lecture today.
The title of the lecture was ``Catching a Thief With and Without Numbers.'' Slides here.
In the second part of the class, we briefly discussed the Shonubi case. Shonubi was found carrying (roughly) 400 grams of heroin at JFK airport in New York. He arrived to JFK on a flight from Nigeria, and his travel record showed that Shonubi made a total of 8 trips between the US and Nigeria. What was he doing on these trips? Since Shonubi was not wealthy and had no persuasive explanation for why he flew so often across the Atlantic, we might think that Shonubi did carry drugs on each of the eight trips. But even if this were true, how much did he carry? This is where things become unclear. Note that determining how much Shonubi carried in total is crucial for sentencing purposes: the more drugs one carries, the longer the prison sentence. That is why -- during the sentencing hearing -- the prosecutor wanted to establish that Shonubi carried more than 400 grams.
The data from US customs showed that most travelers similar to Shonubi -- e.g. those traveling on the US-Nigeria route and those who were found carrying drugs -- carried 400 grams per trip. It is tempting to conclude that Shonuni carried roughly 400x8 grams in total. This is what the district judge thought and thus he sentenced Shonubi accordingly. On appeal, the argument was rejected.
The question of how much Shonubi carried in total was then discussed again during the second sentencing hearing. The second time a more sophisticated statistical model was used (see the handout). If we look at the data from US customs, the smallest drug amount is 42 grams. So, thinking conservatively, Shonubi should have carried 42 grams on his first trip, while on the subsequent trips the amount increased progressively up to 400 grams. According to the model, Shonubi became better and better at carrying drugs. (This is not implausible. Bear in mind that drugs are typically carried in small balloons, which are ingested in one's stomach. So this is a skill that requires learning.) The result, given the model at least, is that Shonubi carried a total of roughly 2,000 grams.
The new statistical argument persuaded district judge Weinstein, who sentenced Shonubi as though he carried a total of 2,000 grams of heroin. Shonubi appealed for the second time, and the Court of Appeals sided with him. The Court insisted that ``specific evidence'' was needed, and that statistics about other drug traffickers (along with a statistical model) did not constitute specific evidence.
But what is specific evidence? One might say that specific evidence is evidence that points directly to the defendant. This is intuitive, but as seen at the beginning of the course, it is hard to make sense of the notion of specific evidence. Interestingly enough, the Court did not offer a definition; it only offered some examples of what would could as specific evidence: live testimony, drug records, admissions, etc. Is this satisfactory?
A distinction that might help in understanding specific evidence concerns ``circumstantial evidence'' as opposed to ``direct evidence.'' Whether this distinction holds water is unclear. But the idea is that circumstantial evidence is evidence about the circumstances surrounding the crime. So, DNA evidence, trace evidence, fingerprint evidence. etc. would count as circumstantial evidence. In contrast, an eyewitness' recounting of what happened during the crime would count as direct evidence because the recounting is directly about the crime, and not simply about the surrounding circumstances.
The district judge -- judge Weinstein -- reasoned that factual conclusions can be drawn both on the basis of direct evidence as well as circumstantial evidence. He then concluded that specific evidence -- which he equated to direct evidence -- was not the only type of evidence which could be used to reach factual determinations, contrary to what the Court of Appeals held. But the Court of Appeals insisted that ``direct evidence'' is different from ``specific evidence'' and that ``specific evidence'' can be both direct and circumstantial evidence.
One argument judge Weinstein used against the notion of specific evidence derives from RULE 401 of the Federal Rules of Evidence. The definition of relevant evidence reads: ``Relevant evidence means evidence having any tendency to make the existence of any fact that is of consequence to the determination of the action more probable or less probable than it would be without the evidence.'' As one can see, this definition does not rely on the notion of specificity; rather, it relies on some crude notion of probability. And statistical evidence -- be it specific or not -- seem to satisfy the rule 401 definition. But if so, why did the Court of Appeal deem it insufficient or even irrelevant?
A possible answer comes from an article by Colyvan et al., which --unfortunately -- we did not have time to discuss. We will discuss it next time.
MAR
Wages and death penalty
- McCleskey v. Kemp (1987)
- Bazemore v. Friday (1986)
- Reading Guide - Week 10
- Handout - Week 10
-
We began our last class with a discussion of the Shonubi case. The facts of the case should be well known by now. Shonubi was found carrying roughly 400 grams at JFK airport in New York. His travel record showed that he made 7 other trips between JFK and Nigeria, so eight trips in total. At sentencing, the prosecutor argued that Shonubi carried drugs on each of the eight trips and that he carried a total of at 2/3,000 grams. Statistical evidence was key to support the prosecutor's argument but the Court of Appeals was unpersuadd and wrote that the stastics lacked 'specificity'. After all, the statistics were about other drug traffickers and not Shonubi himself.
What does ‘specific evidence’ amount to? For one, the notion of specific evidence is intuitive. It is intuitive because the statistics are about a group of people; they are about an aggregate, and not about a single individual. At the same time, specificity is not a clear notion. For consider other types of evidence which are intuitively regarded as specific, e.g. eyewitness testimony. Is testimony really about an individual? A witness might recount facts that are putatively about an individual, but we do not know for sure whether they are about a specific individual. It might be that although he claims to have seen Shonubi, the witness, in fact, mistook Shonubi for someone else.
The article by Colyvan attempts to spell out what’s wrong with the statistics against Shonubi; it attempts to clarify the notion of specific evidence. But, as emphasized in class, I am not sure whether the article succeeds in doing so. Still, here is the general idea. Shonuni can fall under multiple reference classes, e.g. the class of drug smugglers, the class of working immigrants, or the class of people under 35 years of age. Depending on the reference class we select, different conclusions about Shonubi’s behavior can be drawn. If we consider the class of drug smugglers, it is highly probable that Shonubi carried a substantial amount of drugs on each trip. This is because the statistics show that, most of the time, drug traffickers do carry a substantial amount of drugs. But now consider the class of working immigrants. It is not true that most of them carry drugs, let alone substantial amounts. All in all, Colyvan et al. think that Shonuni can belong to multiple reference classes, and equally importantly, they think that it is not clear which class is the most appropriate for the purpose of drawing inferences about Shonubi’s behavior. If so, statistical evidence would be problematic, so its use in court should be restricted.
I asked whether Colyvan's claim can stand scrutiny. Let's consider an eyewitness who tells us about Shonubi. Would the witness testimony be subject to the reference class problem? It seems so. In order to evaluate the trustworthiness of the witness, we need to place him or her in a reference class. Maybe this would be the reference class of the witnesses who testify about drug traffickers, or the class of white witness who testify about Nigerian drug traffickers, etc. Again, depending on the reference class we select, the same witness can be regarded as telling the truth more or less often,and so he can be regard as more or less trustworthy. What is the right reference class in which we should place the witness in order to assess his or her trustworthiness?
Now, if the reference class problem is a problem for statistical evidence, the above argument suggests that it is also a problem for eyewitness evidence. I suspect the reference class problem might apply to ANY kind of evidence. If so, Colyvan’s claim would entail that ANY kind of evidence is problematic and that the use of any kind of evidence in court should be restricted. But this would be absurd. We cannot refrain from drawing conclusions from any kind of evidence. Incidentally, note that this might not be a damning objection for Colyvan et al., but at least it should make us think.
Next, we read a recent article from the NY Times about the proposed changes in the definition of “profiling.” As of now, the police can use profiling techniques during crime investigations, although race cannot be among the factors included in the profiling. Racial profiling is illegal. The proposed changes would include both religion and national origins among the sensitive factors, so that profiling based on religion or national origin would become illegal, as well. In the comments to the article, one reader said that we should make a distinction between (a) targeting people of religion X during the investigation provided that the police has (specific) evidence that the perpetrator was of religion X, and (b) targeting people of religion X without having (specific) evidence that the perpetrator was of religion X but simply on the basis of profiling and statistics. The reader implied that (a) was acceptable, while (b) was not.
For the sake of argument, we challenged the distinction, and more specifically, we challenged the claim that (a) was acceptable but (b) was not. FIRST CHALLENGE: In both (a) and (b), all we have is a probability that a persona of religion X was the perpetrator; whether the evidence is specific or statistical, in both cases the police can arrive at a probability that a person of religion X was the perpetrator. SECOND CHALLENGE: If the (specific) evidence in (a) comes from an eyewitness, the eyewitness, too, can be racially or religiously biased. So even granted that (b) contains a bias against people of a certain religion or national origin, there is no guarantee that there would be no bias in (a). The two challenges suggest that either both (a) and (b) are acceptable or they are both unacceptable. Drawing a line seems difficult.
On the other hand, the distinction between (a) and (b) makes good sense. One point that emerged in class is that profiling and statistics are about the past. They give us information about crime patterns in the past. Using statistics for investigating current crimes is potentially misleading because the current situation might have changed. In disregarding the changes that might have occurred, the police will fall prey to its own pre-conceptions, something like a “tunnel vision” effect. On the other hand, we cannot deny that there must be some continuity between past and present, nor can we deny that presupposing the existence of a continuity is useful while we reason about the world and take decisions in the world.
The third topic of the class was a discussion of two court cases, both centering on discrimination. Bazemore was about wage discrimination, and McCleskey was about death penalty discriminating. A precise statement of the issues at stake and of the evidence presented can be found in today’s handout. We discussed these two cases because they seem to be in tension with one another. Bazemore suggests that regression analysis is is enough to establish a wage discriminating claim with preponderance of the evidence. In contrast, McCleskey suggests that regression analysis alone — no matter how sophisticated — is not enough to establish that a jury has discriminated against a defendant (while deciding on the death penalty). What is the difference between the two cases, except that one is about wages and the other about the death penalty? It is far from easy to understand the difference.
Three ideas emerged during our discussion.
First, wage discrimination cases are governed by Title VII according to which the complainant should make a prima facie case of discrimination. The respondent can rebut the prima facie claims. Regression analysis is typically regarded as sufficient to make the prima facie case. In death penalty cases, instead, title VII cannot be used, because there is no room for a rebuttal. Here the respondents would be the jurors or the justice system itself, which are not in a position to rebut a prima facie claim (say) that the system discriminates against blacks. This asymmetry can motivate why McCleskey requires that, in death penalty cases, the evidence of discrimination should be very specific, and regression analysis is not enough.
Second, regression analysis can establish the RISK of discrimination. In wage discrimination cases, establishing risk of discriminating is thought to be enough to make a prima facie case; not so in death penalty cases. In the latter cases, it seems, what needs to be established is not simply the risk that the defendant was discriminated against, but rather, the fact that the defendant was, in fact, discriminated against. In other words, what needs to be established is a specific intent to discriminate against the specific defendant. This can again motivate the need for specific evidence in death penalty cases.
Third, one might argue that McCleskey did not receive a fair trial because the regression analysis showed how the Georgia’s justice system was racially biased. One response to this line of thought is that the system’s fairness only requires that certain PROCEDURES should be uniformly applied to all defendants. One could argue that, in this sense, McCleskey did get a fair trial. Fairness, one might say, is about the procedures that are in place, and not about the actual outcomes. Fairness would not require equality of outcome, just equality of procedures. Regression analysis measures the outcomes, not the fairness of the procedures themselves, so one might conclude that regression analysis is irrelevant for the issue of fairness. Still one might wonder. If the outcomes show a systematic racial biased, isn’t it plausible to explain this with the hypothesis that the procedures themselves are racially biased?
At the end, I asked each of your to share some thoughts about the class and what you’ve learned. At the beginning of the course, many of you had high hopes in the application of probability and statistics in the courtroom. But at the end of the class, many of you became disillusioned. The consensus seemed to be that we should really be careful with probability in the courtroom. Further, many of you initially thought that a high probability of guilt should be enough for a conviction. At the end of the class, many of you were convinced that understanding standards of proof probabilistically was a mistake. And finally, some of you thought that taking this class helped in critically assessing the process of legal fact-finding--—and maybe you’ll be a better juror if one day you are called for jury duty.